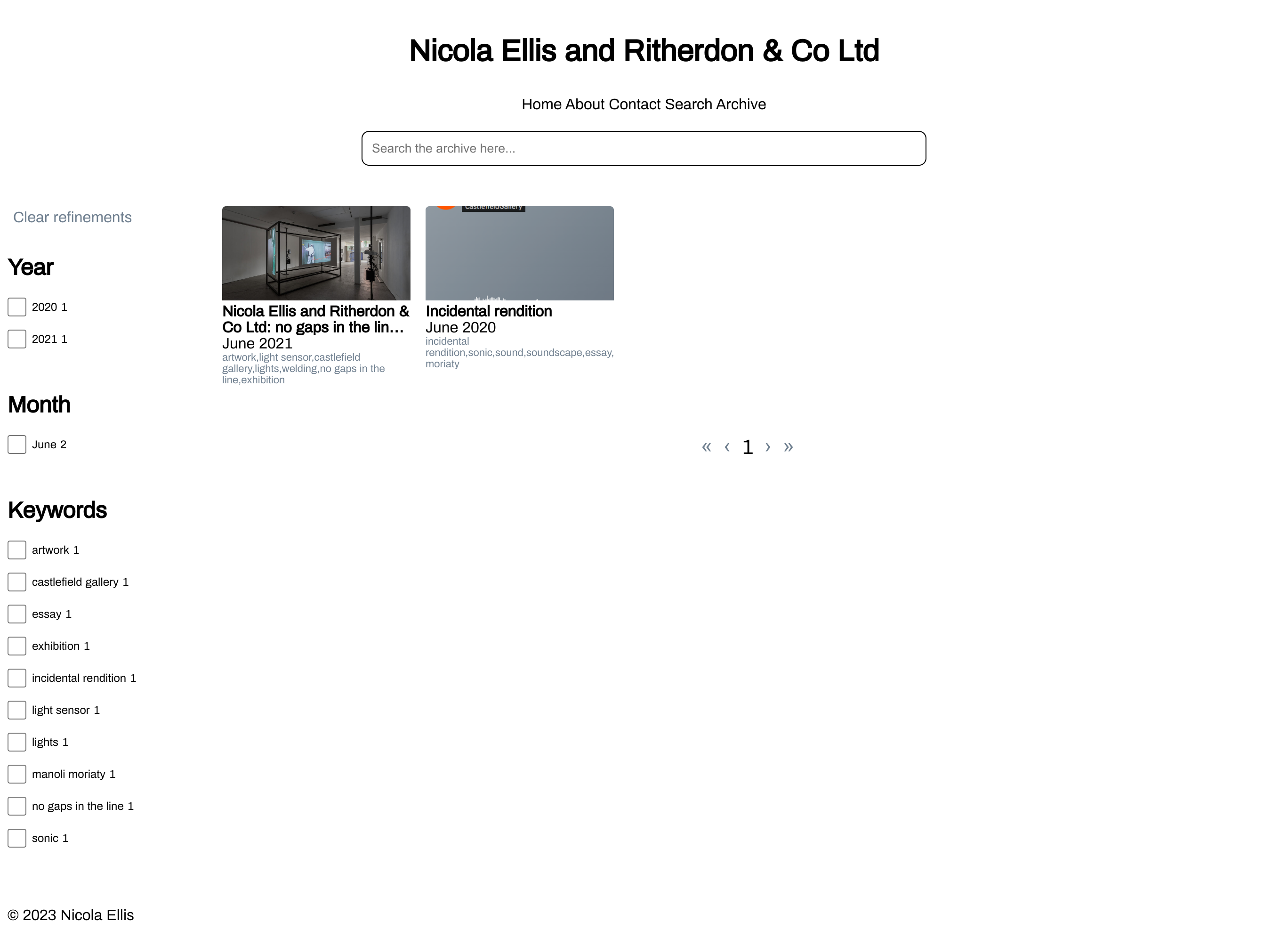
 Figure 1. The beginnings of the Nicola Ellis and Ritherdon Archive.
Figure 1. The beginnings of the Nicola Ellis and Ritherdon Archive.
Ritherdon
Archive is
essentially a website ran by Nicola Ellis. Its
purpose is to preserve as much data/context/output from the Return to Ritherdon
Project as possible. If you would like to know more about the Return to Ritherdon Project, use the following links:
From my point-of-view, the Ritherdon Archive is a blogging site. Or, one of the
main aims of the project was to provide something akin to WordPress
Basic. Nicola wanted something which operates like
WordPress without all the features she never
touches. This is the result.
I wrote the site in Common Lisp and used SQLite database. One of the main
reasons for using SQLite was its portability. This (Ritherdon Archive) website
includes a purpose-built 'snapshot' feature which makes it easier to back up the
site's data -- as well as export it.
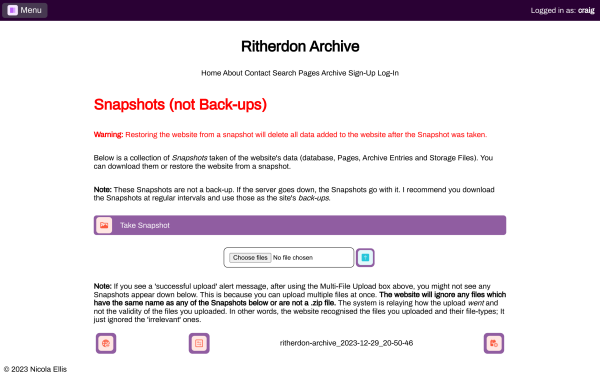 Figure 2. Take snapshots of the website's data at that moment of time.
Figure 2. Take snapshots of the website's data at that moment of time.
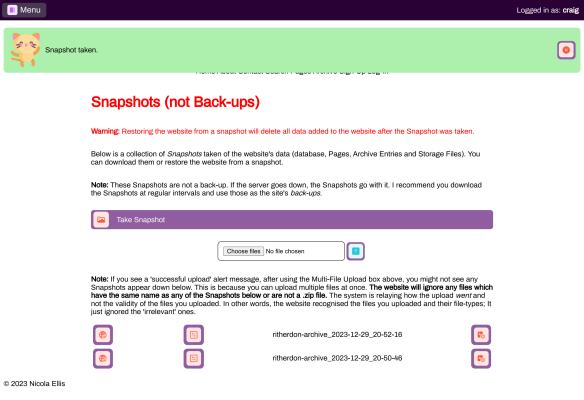 Figure 2a. Restore and download snapshots.
Figure 2a. Restore and download snapshots.
Another aspect of archives -- which determines how useful they are -- is how
easy it is to find stuff in it. Because of this, I've integrated
Meilisearch into the site. This means viewers of
the site can fuzzy search its contents. It's, also, an optional feature.
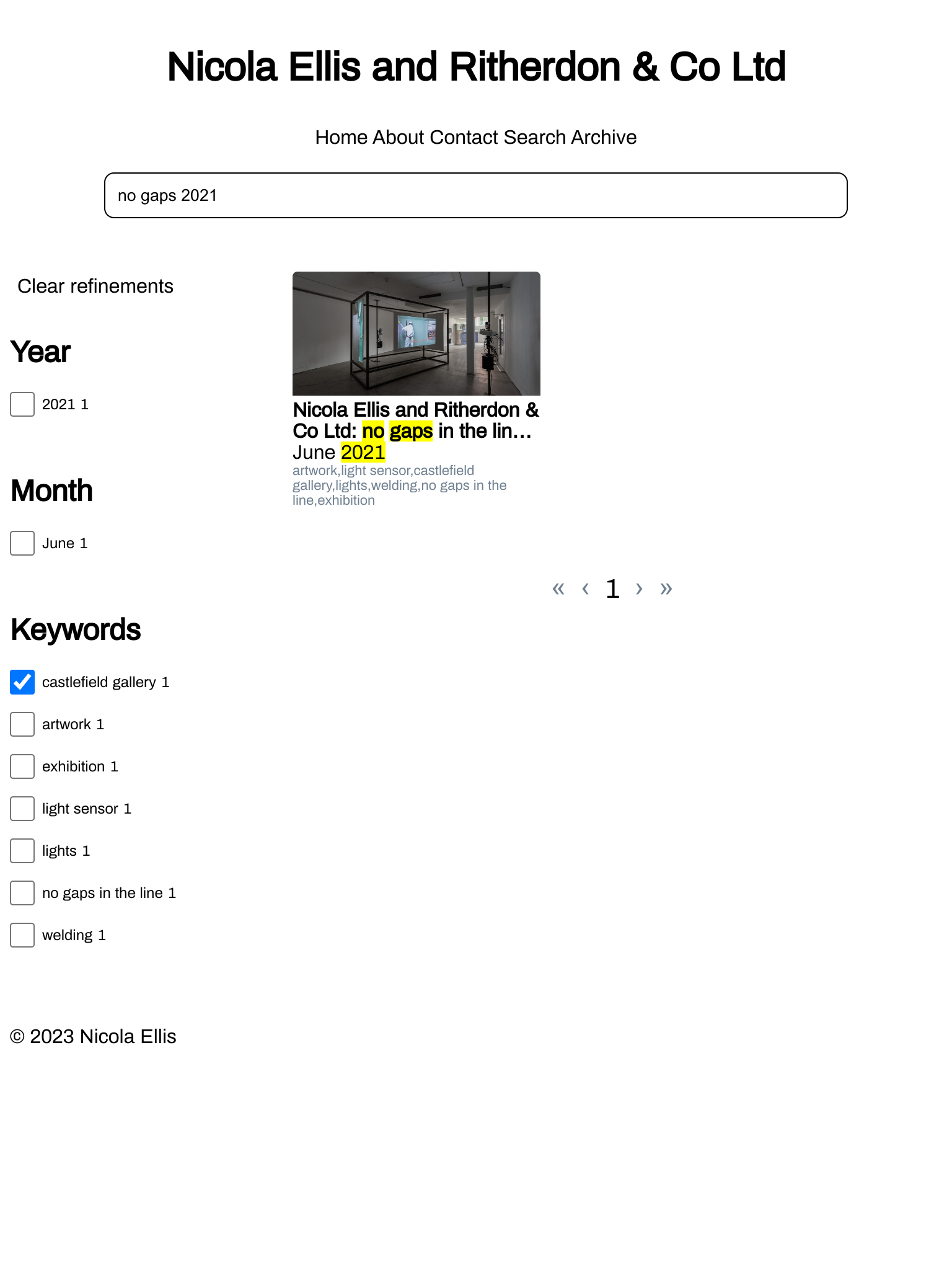 Figure 3. Use the (optional) fuzzy search feature to find things on the website.
Figure 3. Use the (optional) fuzzy search feature to find things on the website.
I've included an in-built 'filter search' feature if you don't want to run a
Meilisearch instance. The filter is not as fancy as the Meilisearch features,
but it helps the site's viewers to quickly find a particular blog post.
 Figure 4. The site has a filter feature which you can use if you don't want to
use the (optional) fuzzy search features.
Figure 4. The site has a filter feature which you can use if you don't want to
use the (optional) fuzzy search features.
While the Ritherdon Archive project has a specific purpose, the code for this
site is a good starting-point to create a more generalised blogging site. If you
know Common Lisp and are familiar with
Caveman2 and
Mito, feel free to fork the project.